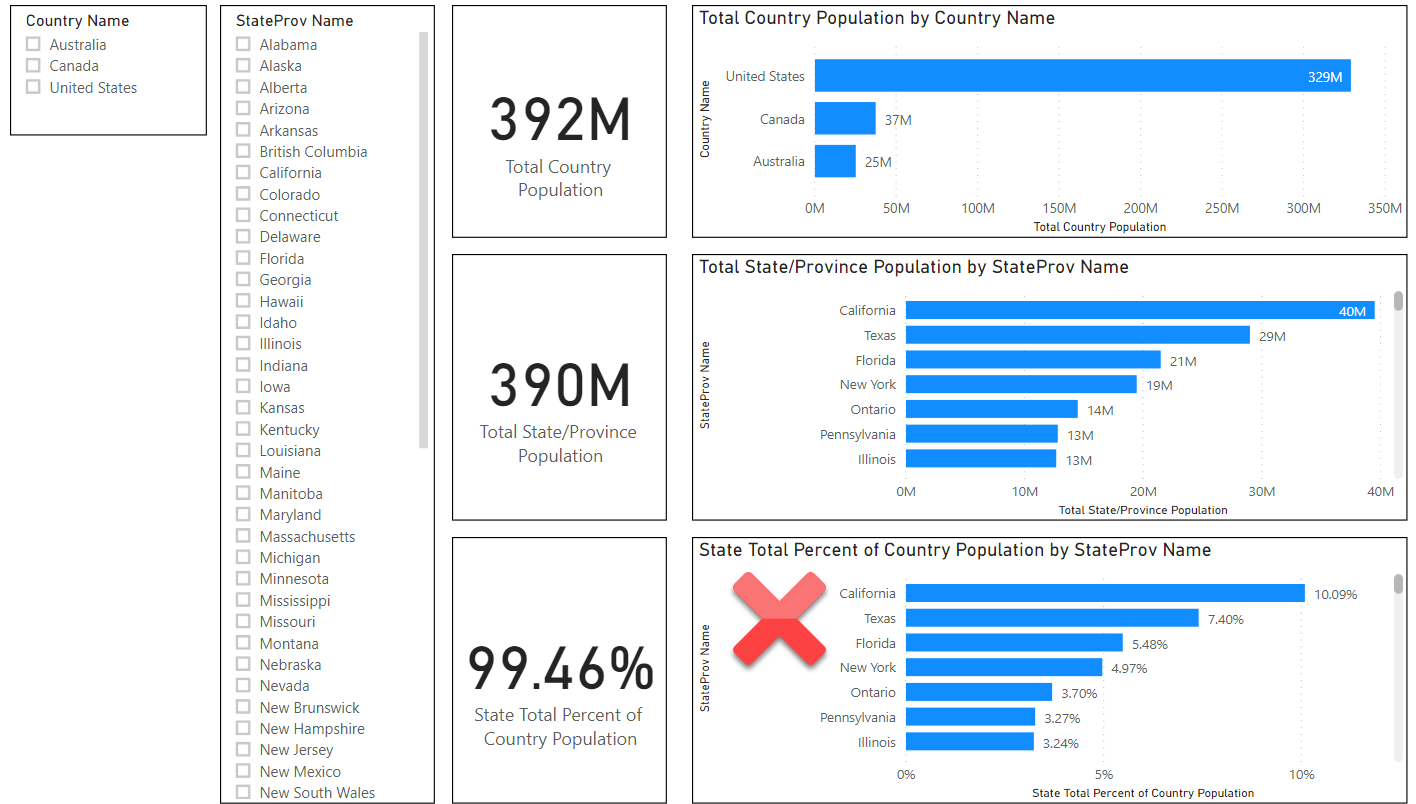
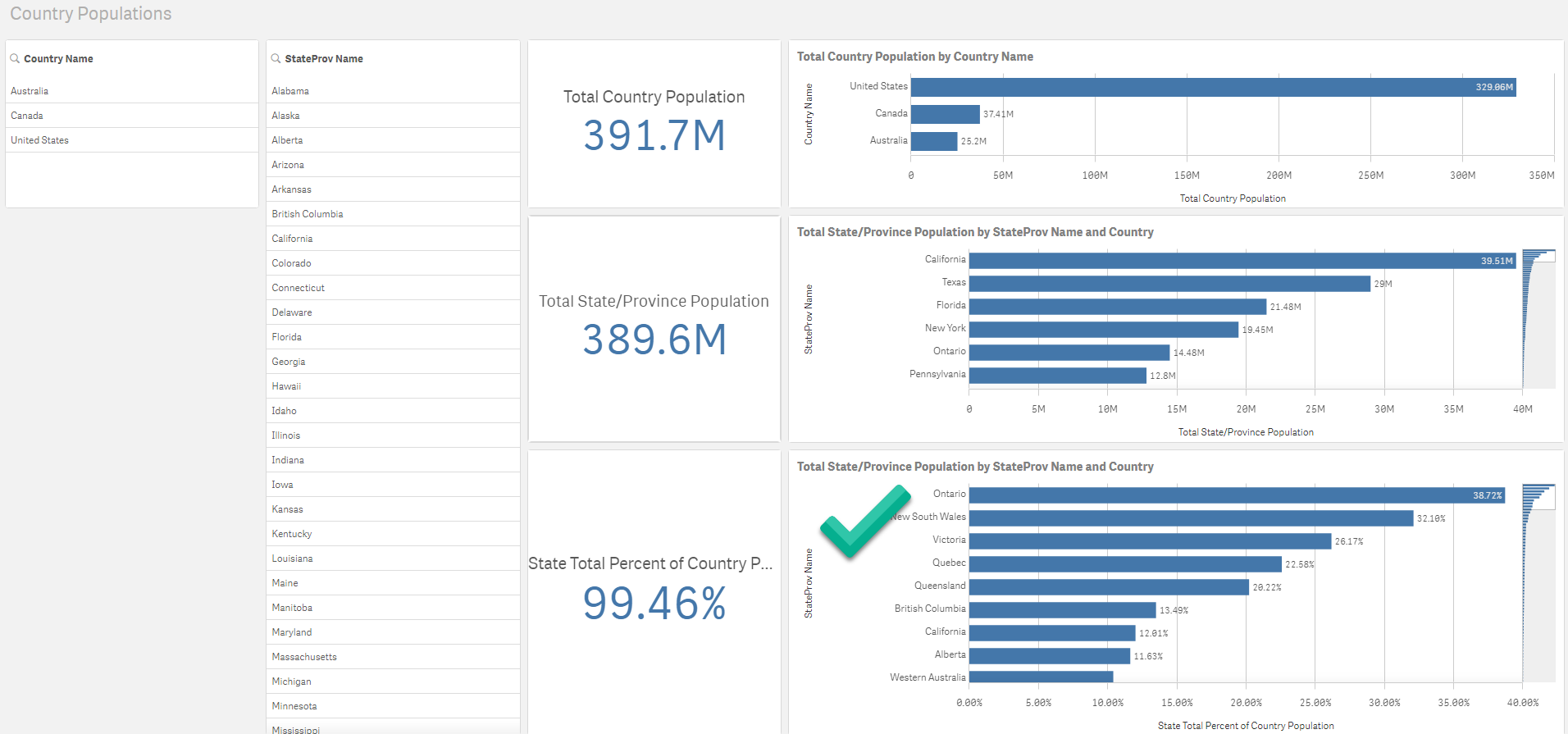
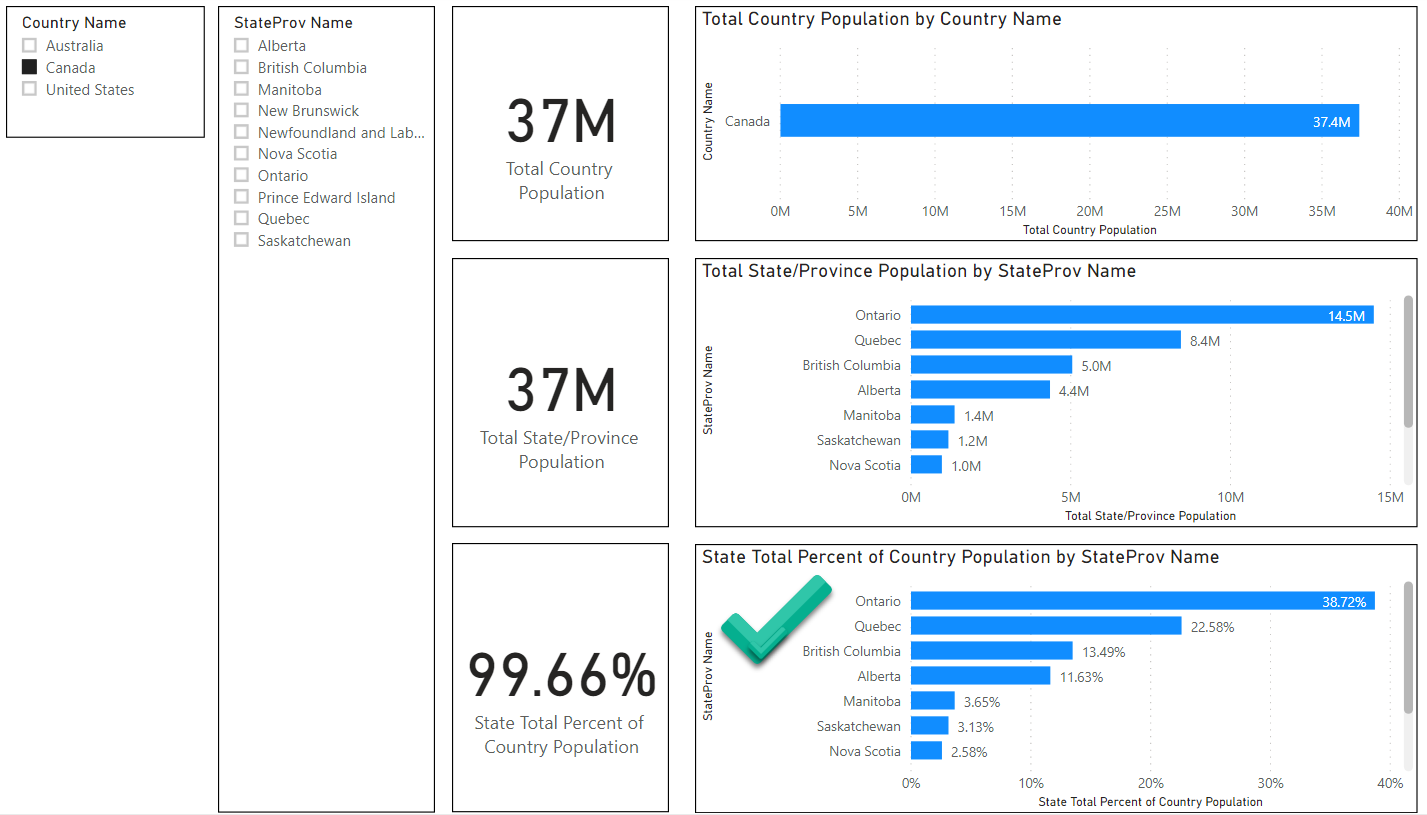
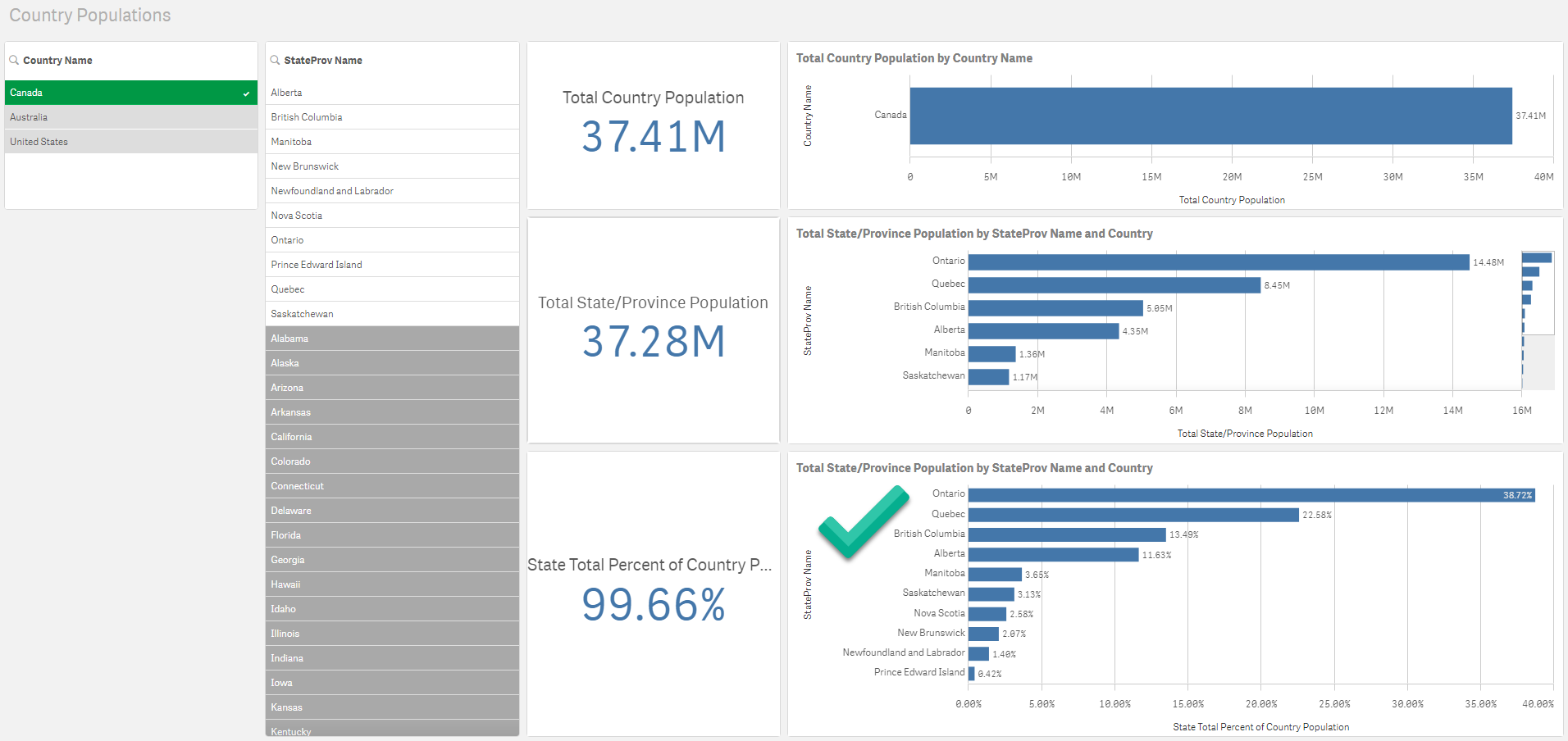
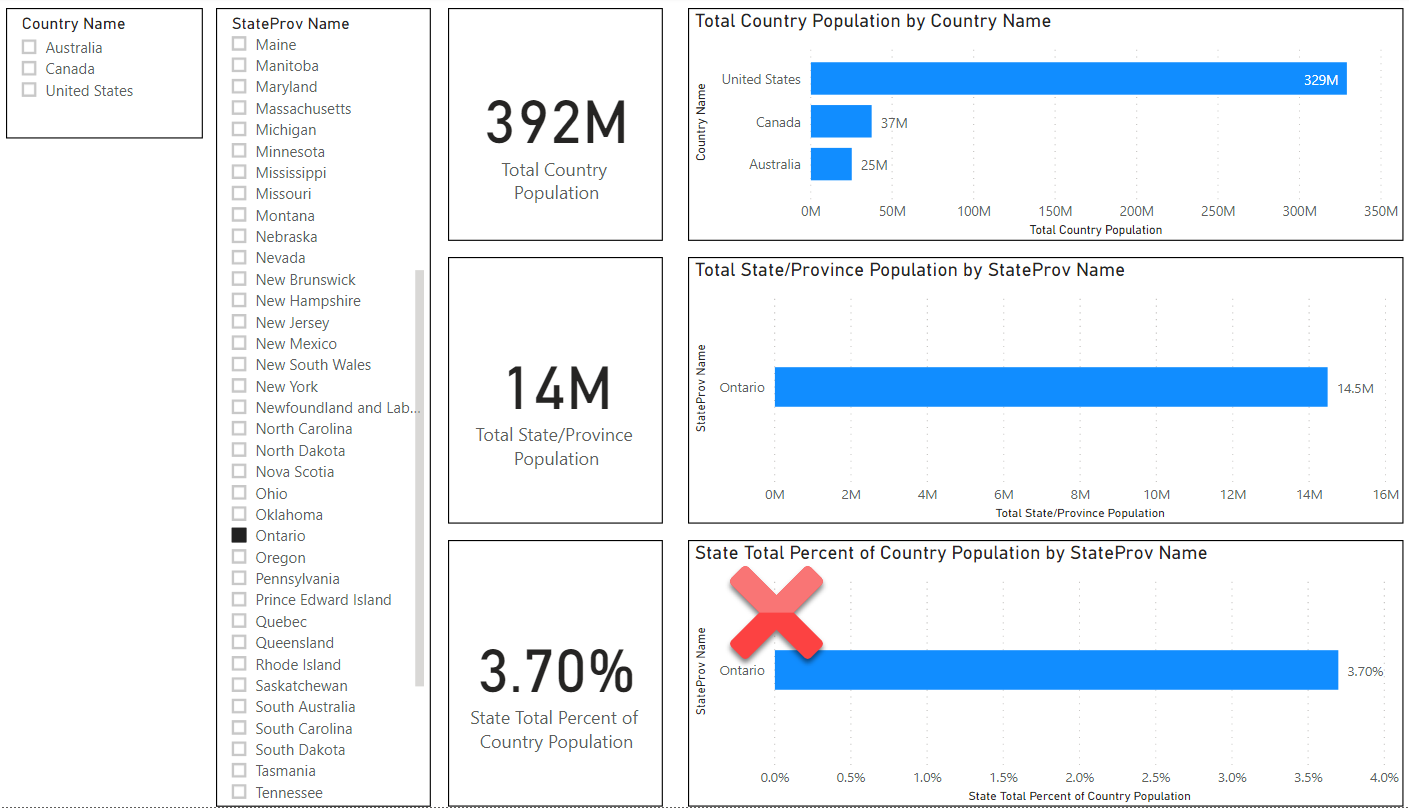
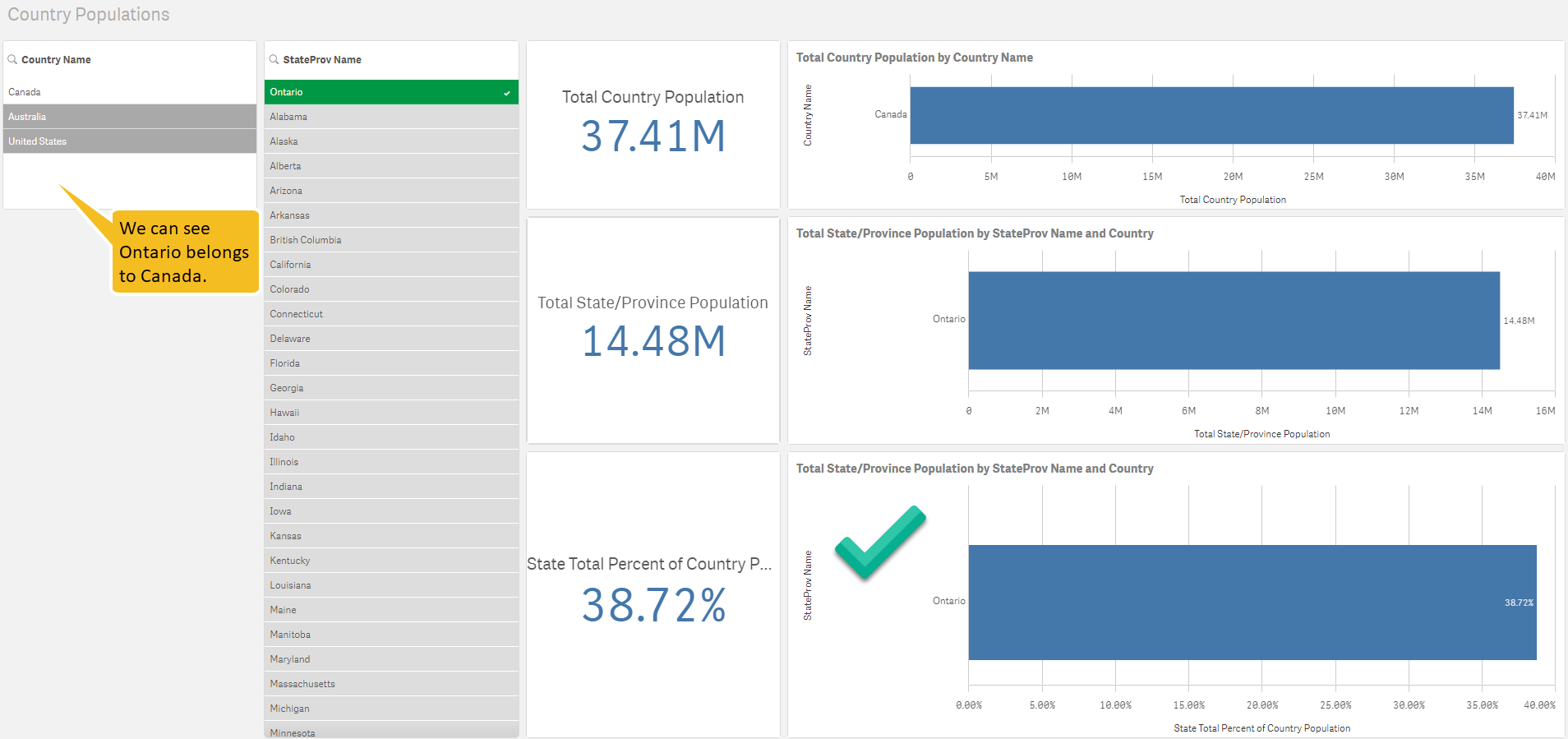
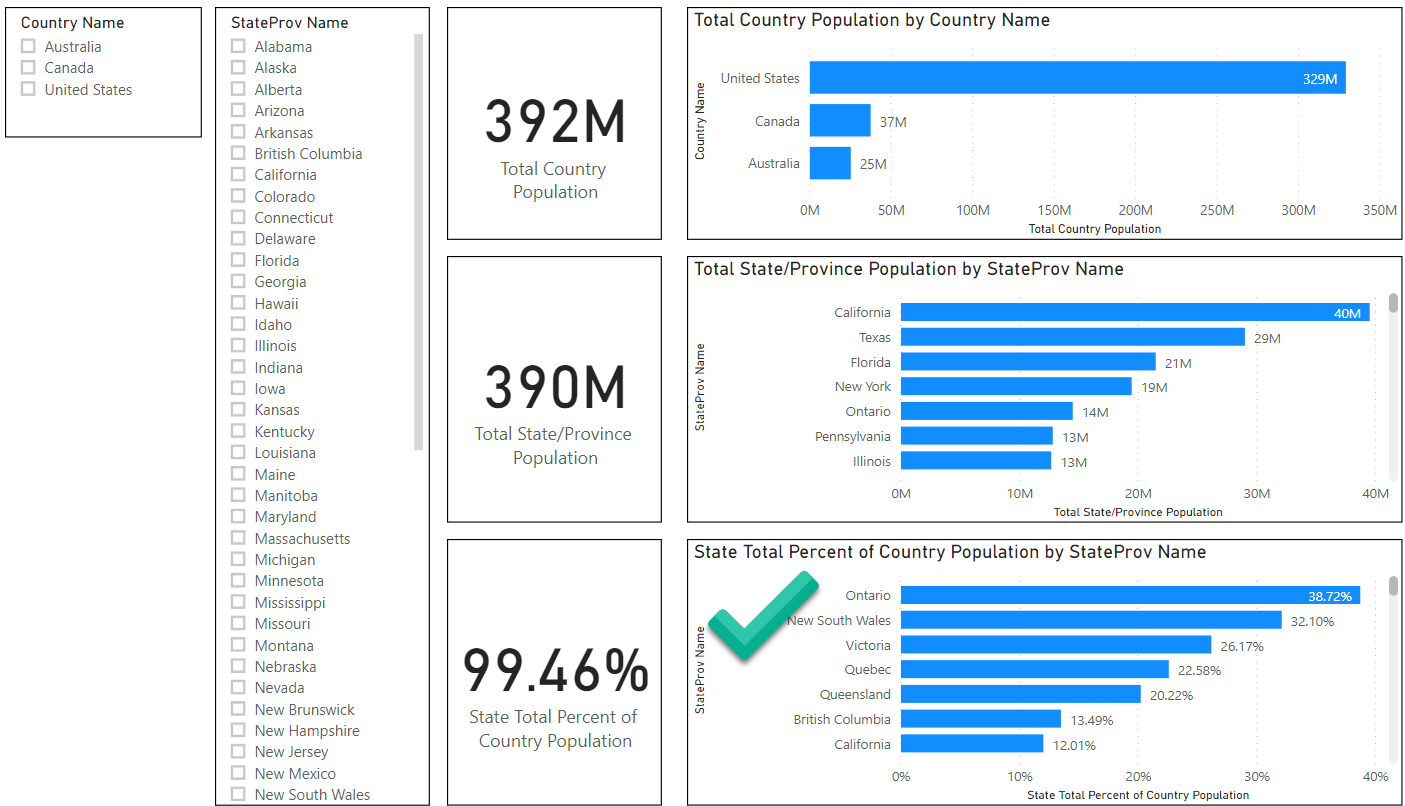
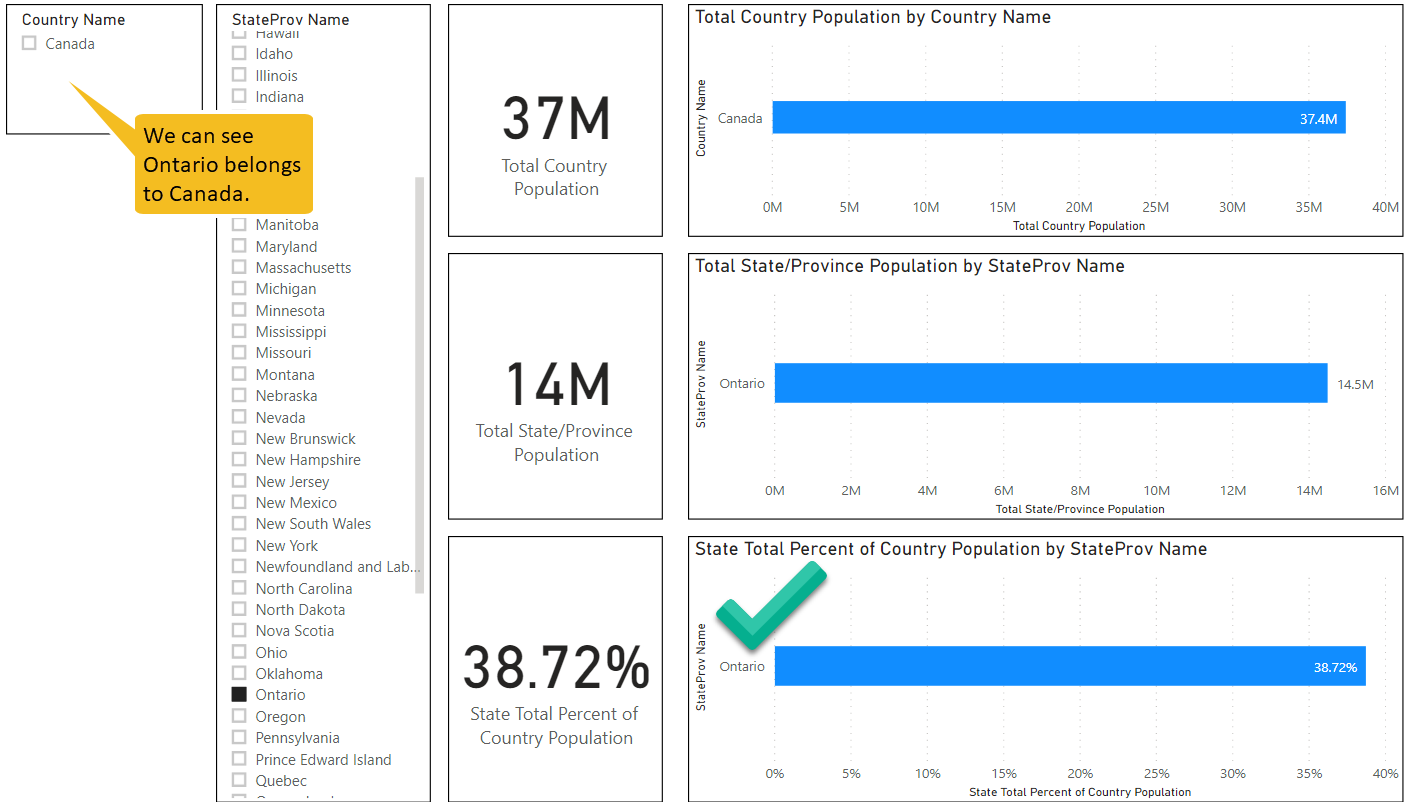
TL/DR: Snowflake’s $63 billion valuation shortly after their IPO is primarily based on user network effects rather than its database innovations. Tech journalists and other analysts don’t want to sound cynical by reminding people of “lock in” and would rather discuss innovative features. But technical innovation is a distraction here. Whether you are an investor or a customer, it behooves us to understand the subtle nature of network effects and lock in or else we are doomed to lurch from one locked-in vendor silo to the next. But there is reason for hope.
A few weeks ago I was listening to a podcast interview with Bill Gates.
At one point the conversation turned to Bill’s relationship with Warren Buffett. Gates recalled an early conversation he had with Buffet where he mentioned that the ‘Oracle of Omaha’ was struggling to understand how Microsoft could compete with IBM in the long run. This was in 1991 and IBM at that time was still considered the juggernaut of IT and the conventional wisdom was still “nobody got fired for buying IBM”.
While Gates didn’t come out and say it explicitly during the interview, the reason of course has to do with network effects or more specifically what we now refer to as user or vendor “lock in”.
For the same reason that Microsoft was able to compete with and eventually displace IBM, was the reason that Microsoft was nearly broken up in the late 1990s. Once a critical mass of users and applications is reached, it is nigh impossible to break that network without some kind of technology disruption occurring, in which case a new technology or vendor takes over and the cycle repeats itself.
Network effects, lock-in, and barriers to entry for competitors are something many people are aware of but the tech journalists and other analysts don’t always remind us of this when I think they should.
My introduction to the network effect concept came in the 1980s when I learned that the inferior VHS videotape standard had displaced the superior BetaMax format that Sony had developed. The story goes something like this (I am recollecting from memory, apologies for any errors ): Sony had developed two video cassette technologies: VHS and BetaMax. VHS was deemed a prototype and not worth protecting IP. BetaMax was the quality product Sony was aiming for. So VHS was out there as a viable standard but initially had no backing to speak of. When the adult film industry realized they could sell movies directly to customers through home video, their efforts were stymied when Sony refused to allow its BetaMax to be used for distributing “lewd and unsavoury” content. With no access to BetaMax the adult film industry simply took the path of least resistance and distributed through VHS. Since there were no IP restrictions for VHS, this opened the standard to other companies like RCA, Philips, Panasonic and other home electronics manufacturers to manufacture and sell their own VCRs.
Within a few short years VHS became the de-facto standard for home video.
As an epilogue I do recall BetaMax hanging on for a while by emphasizing the quality aspect of their invention. However, even that was displaced by the LaserDisc format which could provide both quality and features that neither VHS nor BetaMax could provide. By the mid nineties there were two home video “networks”: Low-end VHS tapes for the masses and high-end LaserDiscs - which offered superior picture and sound quality, directory commentary, and elaborate liner notes - for film buffs. The esteemed Criterion Collection was effectively borne out of the network effects from LaserDisc format.
By the late nineties the DVD format began to pick up steam and because DVDs could offer LaserDisc features at VHS prices, both of the latter standards would soon succumb to the same fate at the BetaMax format.
An episode of The Simpson’s has a funny joke about this where we see a garbage dump with piles of VHS tapes, LaserDiscs, DVDs, and an empty area with a sign that says “Reserved for Blu-Ray”.
I suspect (even hope) many readers just skimmed through the last two paragraphs. As anyone who cares or follows the technology industry knows, network effects are the name of the game in the modern world of technology.
In a sense it has been like this for a while: in the “olden days” you could be shrewd inventor like Morse or Edison and work the levers of the patent system to protect your invention and build up a network effect.
Alternatively, you could be like IBM or Apple and develop a strong reputation and brand that keeps customers loyal while scaring people away from competitors products.
In ancient times (and even still today) innovation was limited to what could taught and passed on. Hero of Alexandria invented the steam engine nearly 2,000 years before it would be re-invented. He wrote down instructions on how to make one, but anyone who took the time to build one probably kept the knowledge to themselves. We even romanticize such inventors as “wizards” when many of them were really just knowledge hoarders protecting their secrets.
While I have my reservations about Edison, IBM, and even Apple, I think building businesses on patents and strong reputations is not necessarily a bad thing for the simple fact that this dynamic propels innovation. The inventors in the pre-modern world would also have to compete.
On the other hand, businesses that are able to exploit network effects to grow quickly are also worthy of praise. These companies which often come out of nowhere can quickly shake up otherwise calcified industries. Everyone loves an underdog, especially when it beats the champ.
But taken to extremes all of these things: patents; brands; and network effects can end up stifling competition or worse, creating institutions that society depends on but which effectively undemocratic. Companies like Facebook, Google, Microsoft, Amazon, Apple, and I’ll put Western Union in there for good measure all leverage network effects to great success.
Do you think it’s possible to out-innovate Google with a better search engine? Maybe it’s possible, but you also have to realize that Google has the world’s largest database of user search history which is now the main driver of search results. Good luck in getting that, but maybe it’s possible?
Apple has hundreds of thousands of developers locked into its App ecosystem (which only competes with Google).
Facebook I don’t need to explain, they don’t even bother boasting about the size of their network any longer and basically act like the Saudi Arabia of social networking.
Amazon in some ways has the most genuine competition to deal with. But when you compare it to its next best competitor Walmart, Amazon is miles ahead in terms of its integration between supply chains, warehouses, and delivery chains, not to mention the fact that Amazon also has its own cloud infrastructure “AWS” it can cheaply tap into for all of its digital needs.
The trillions of dollars these companies are worth are based mostly, in my opinion, on these network effects more so than any particular technology or innovation you can point to. We live in a world of that is increasingly substituting glorious free market competition with the less splendid monopolistic competition.
Whenever I see talk of a new start-up, I feel like the honest question to ask is: How does this company combat existing network effects that are working against them and how can they bring about network effects that lock their customers in going forward?
When I phrase it like this, it sounds a bit anti-capitalist or crude to even wish for lock-in.
It is so obvious that this is what is happening and yet I rarely see this level of frankness when new technologies are discussed.
In other words, I believe the way we talk about technology and innovation is dangerously infused with magical thinking that ultimately plays into this dynamic.
This now brings me to Snowflake, the recently public IPOed cloud database company.
As of October 2nd 2020 on the NYSE, “SNOW” closed at $227 with a combined Market Cap of $63 billion.
That is an extraordinary sum of money for a relatively new technology that was founded in 2012 (8 years old).
Compare this to other companies in the business data analytics on October 2nd:
- Domo (DOMO) $1.1 billion (founded in 2010)
- TeraData (TDC): $2.4 billion (founded in 1979)
- Looker was recently sold to Google for $2.6 billion (founded in 2012)
- Cloudera (CLDR): $3.28 billion market cap (founded in 2008)
- Databricks, still private but last valued at $6.2 billion (founded in 2013)
- Alteryx (AYX): $8.1 billion market cap (founded in 2010)
- Tableau was recently sold to Salesforce.com for $15.3 billion (founded in 2003)
- Oracle (ORCL) closed with a market cap of $177.1 billion (founded in 1977)
- SAP SE (SAP) closed with a market cap of $189.4 billion (founded in 1972)
Based on this smattering of companies, it would seem like Snowflake is an outlier in the data & analytics space. It’s a newer company, but is valued at least 4 times as much as it’s closest peer (Tableau). On the other end of the spectrum Snowflake is one third of the value of Oracle and SAP, both highly established businesses with deep customer bases.
I can point out many companies that would struggle to keep operating without Oracle and SAP, so their hefty valuations make sense to me. I can also look at a company like Tableau and appreciate its value, mainly based on the strong brand image it was able to cultivate and the loyalty this has generated.
With Snowflake I am not seeing - at a ground level - the level of business process lock-in that Oracle and SAP enjoy. Nor am I seeing the level of brand recognition that Tableau has among business users (although that has ironically been boosted by the IPO itself).
Furthermore, the vast majority of IT departments (and businesses in general) tend to prefer homogenous architectures. This means that they would rather purchase from a single vendor with “one throat to choke” than deal with multiple vendors and the friction that comes with cross-vendor integrations. This means that if SAP forms the centre of business functions and processes then you would buy SAP products even if they are not quite as good as the competitor’s product. I’m not saying this is always the right thing to do, but it often is the most efficient approach, and more to the point it’s a more easily defensible position, a la “Nobody ever got fired for buying IBM”.
So how does Snowflake overcome these huge barriers and go on to be valued at the $63 billion?The answer of course is network effects.
But how exactly?
Before I answer that question, I’ll just explain briefly how Snowflake works and how it is different from traditional databases.
Most databases combine both the data (storage) and the compute power (VM [virtual machine]) into a single service. While modern data warehouses do a decent job of scaling large numbers of users and workloads, they do not scale elastically. What this means is you need to reserve ahead of time the amount of compute hardware for the database. This means you are often paying for unused compute power and it can also mean that you might hit an upper limit if too many users are querying the data warehouse at the same time. It’s not a common thing but it happens, and quite frankly it is rare to see problems that cannot easily be fixed by simply adding more hardware, which is can be accomplished with a few clicks on cloud platforms. You can even automate this scaling. There are also benefits to this constraint in that costs are more predictable and easier to budget for.
Nevertheless, this user isolation concern has been known for decades and techies tend to gravitate towards these types of problems, even if they are mostly theoretical. Originating from Google and beginning around 2010, the concept of a “Data Lake” began to emerge as the solution to this problem. The idea was (and still is) that you run programs on clusters of VMs (i.e. one ore more cloud compute nodes) and read and write from a specialized file system known as HDFS (Hadoop File System, [originally the Google File System]) that is designed for both resilience (i.e. protection from data loss) and performance. This means that data developers and data analysts alike can blend data from multiple sources (essentially just flat files like CSV files, but also binary optimized flat flies like ORC and Parquet formatted files), and then write back out their results as other flat files. However, the problem with this approach is that there has never been a consensus for how developers manage the Metadata that surrounds these flat files. It’s a bit like asking hundreds authors to fill up a library with books but without any indexing system. Eventually you will be left with a library teeming with books but with no ability to find what you’re looking for or even understand who wrote what and why.
Metadata management is a crucial service that databases provide (often in sub-system known as the “information schema”) so users can quickly understand how tables are related and what assumptions we can make of their their contents.
The way in which Data Lake centric platforms solve this problem is to create a managed Metadata service that would provide this service. If you have heard of “Presto” or “Hive” or “Impala”, these software systems piggyback on Data Lakes and provide a Metadata service layer which allows data developers to work with Data Lakes while maintaining the crucial Metadata in a centralized location available to all other users. For example, Databricks and Cloudera both allow their users to create “Hive” databases, whereby all the data is stored in a Data Lake and the computation costs are charged back to the user.
I would argue that this approach is as good if not better than the Snowflake DB approach. The reason is that when you are querying Snowflake data you need to use Snowflake’s own database compute engine (regardless of the fact that it is perfectly isolated). To be fair to Snowflake, they have built an engine that performs well under the vast majority of situations.
But the Data Lake approach has no constraints when it comes to computation or how files are being accessed. You also don’t need to go through the Metadata (e.g. Hive) layer if you don’t want to. For example, you could develop specialized file formats and corresponding compute engines that encode and decode those files for specialized applications that don’t fit neatly into pre-existing patterns. Again, to be fair to Snowflake they can and have extended their platform to allow this type of customization too, but you have to wait for Snowflake to do this.
Let’s get back to this extraordinary market valuation of $63 billion. If there are established alternatives to Snowflake as we just discussed, and those alternatives are already baked into the eco-systems of major cloud vendors (e.g. Databricks and Cloudera are already baked into Microsoft Azure), and it is undesirable to use vendors outside of the dominant platform, then why would so many people abandon homogenous architectures and complicate the IT landscape with Snowflake?
The answer I believe comes down to something much simpler: Convenient user access. Not unlike VHS videotapes.
A pattern I often see play out in the modern enterprise goes something like this: Technologists (researches, consultants, early adopters, IT staff, etc.) hear about some bleeding edge new technology that “all the cool kids” are using. This is often associated with some kind of hype cycle, like “big data” or “machine learning” or “blockchain”. Then there is a rush to evaluate and even adopt the technology. Some “proof of concept” or trial is produced that might show some potential. Usually there is a one-time data dump/extract provided along with a few business users who are onboarded with the specific purpose of evaluating the potential of the technology.
But then when the proof-of-concept is over and the business users themselves are left to their own devices, they rarely go back and use or even ask for the new technology. Occasionally a user might mention it or even ask if they can use it, but more often than not they will go back to data sources they readily have access to and tools they are comfortable with.
With all of that said, doesn’t Snowflake also have the same problem, and isn’t it made worse by the fact that Snowflake does not (yet) have the advantage of being sold under the banner of a big cloud provider like Microsoft GCP or Amazon AWS or Google GCP?
Yes and no.
Yes, because there is much of the same type of friction you normally run into when sharing data within the organization or enterprise.
No, because there is significantly less friction when you are collaborating with people outside of the organization or enterprise.
It is this cross-organization data collaboration where Snowflake really stands out and where I can see justifying it’s astronomical Market Cap of $63 billion.
Allow me to elaborate…
The challenge with most modern data platforms is they do not work out-of-the-box with most data tools (e.g. Excel). Instead, the data developer or data user must adjust to a new way of working that is often more awkward than the old way. For example, take that “Data Lake” I was mentioning earlier. To get data into our out of a Data Lake requires special desktop tools (e.g. Azure Storage Explorer) and command line tools that most business analysts don’t have access to. Since these platforms were designed by technologists for “data scientists”, they often lack many simple features most business users take for granted and often feel clunky. For example, if you want to open a file from Azure Data Lake Store, you can’t just browse using Windows File Explorer and then pop open a data file in Excel. Instead you first need Azure Storage Explorer (which may not be available as a standard Enterprise application) and then even if you get it you need to download the file locally first before being able to peer into its contents.
The point being, no matter what modern Data & Analytics platform you are using, there will be some change to the way you work. Thus in this scenario it doesn’t matter if you are using a Microsoft Data Lake or a Snowflake DB.
Now here is where things get interesting. Once you pivot to using a modern Data & Analytics platform, whether it’s Azure Databricks or Azure Synapse or Google Big Query or Amazon RedShift, if you decide at some point that you need to collaborate with groups or individuals who are outside of your organization (or perhaps even in other departments), you start running into brick walls.
For example, let’s say you are an insurance company that wants to share data to related to fraud for the purpose of catching serial fraudsters (this is a real thing btw). Basically your only option is to find some agreed upon data store that is deployed specifically for this very purpose and that requires building data pipelines to populate and maintain. Even keeping a single table refreshed daily would be a big ordeal given all of the concerns that normally are associated with moving data over the public Internet.
But you might think “Hey could we not just provide some kind of guest account into the Data Lake or whatever the database platform we are using?” The answer is “Yes, but.” It’s not so simple is for security reasons. Namely, most cloud Data Platforms are really just one of many components that are managed under a common cloud service for a given “tenant”. For this reason the big cloud providers (Microsoft, Amazon, Google) tend to put up many barriers to external users from logging in easily. By default there are network firewalls and what are known as “conditional access policies” that will take into account your device, location and other factors and require you to perform “multi-factor authentication”, and that’s even if you can get past these policies to begin with. These cloud platforms are designed - by purpose - to minimize friction internally while introducing much friction externally. That external friction is done in the name of security but it also has the effect of nudging people into using more of the cloud vendor’s tools.
This is where Snowflake really shines: It is designed to allow data sharing across customers while not compromising security. While this might sound like something that only applies to cross-organization (internet) sharing and collaboration, it can also apply to intra-organization (intranet) sharing and collaboration. This is because all of those Cloud Data Platforms I just listed tend to be very modular and isolated in their design. These days most organizations have several Data Lakes and other Big Data platforms, but those Data Lakes are often just silos used by only a small number of persons. Contrast this with Snowflake which only behaves like a silo if you want to it, but the moment you want to share data with another Snowflake user, whether they belong to your organization or not, you have the simple and easy option to do so. To be clear, it is possible to lock Snowflake down and make a silo if you want it to be, but it’s also much easier to change those settings when you don’t. The architecture never commits you to the extreme form of isolation that the other cloud platforms do.
While we’re on the topic, I should also point out that Snowflake has another advantage over Data Lakes (which is the alternative that most closely matches Snowflake’s approach): With Snowflake you have fine grained control over what specific rows and columns you want to share, whereas in the Data Lake world, the most granular object is a flat file (table), which tends to made up of many rows and columns. Yes, it is possible to create flat files that are a custom materialized “view” into the data. But you would need to have a data pipeline that keeps that document refreshed on a regular basis. The “custom view” feature in Snowflake (same as RDBMS VIEWs) allows data developers to rapidly and securely collaborate without requiring any “accidental complexity” from data pipeline scripting to creep in.
So what are the implications of all of this?
For Snowflake, if they can get to a certain critical mass they could get to the tipping point where their service simply becomes a cost of doing business. At that point their $63 billion market cap will make sense and many investors might even be wishing they had bought sooner.
This is what Dropbox (NASDAQ:DBX) has been trying to do for a while. Their current market cap is $8 billion down from a high of nearly $17 billion in June 2018.
But Dropbox is more of a consumer technology, and consumers are fickle and don’t really depend on storage services the same way, because very few people maintain their own software systems that manage data.
Snowflake is not consumer data storage service like Dropbox (btw, I am a fan of Dropbox and wish them well) because Snowflake is much more plugged in to Enterprise IT. Snowflake has more “lock in” potential.
I’m sure Snowflake knows this and is using its IPO money to pursue this “winner take all” end game.
But what about the big cloud vendors, surely they are working on something to combat Snowflake?
There are two main challenges they are up against:
- They definitely need to make their existing data platforms more thoroughly elastic. Platforms like Azure Databricks works more like this, but deployment and administration is not as streamlined as it could be when comparing against Snowflake.
- This can be challenging but it’s very much a tractable problem.
- They might need to figure out a way to make cross-organization sharing easier while not compromising security for the other components in the same cloud platform. This is a much harder problem to solve because of all the trade-offs involved. A solution that might benefit data sharing in a data warehouse or data lake might create vulnerabilities or complexities elsewhere.
My advice to these giants would be to play to their own strengths and reduce the friction within their own service perimeters. Earlier in this post I mentioned how Microsoft Azure business users must use Azure Storage Explorer to access data in Azure Data Lake Stores. I should also point out that Azure Data Lake Store itself only supports up to 32 users or user groups from a security standpoint. As a result it’s now common to see dozens of Data Lakes and other data platforms - all silos within the same cloud vendor - sprinkled throughout various departments.
If Microsoft, Google, and Amazon were to focus on these friction points they wouldn’t need to build a competitor to Snowflake.
Instead what I see is a half baked approach whereby business users are nudged towards more business friendly platforms like Microsoft 365 (formerly Office 365) and Google Workspace (formerly G Suite) while leaving the real power tools for just the IT department.
The so-called Data Scientist is basically stuck between these two worlds and often will just resort to running local Data Prep tools on their laptop like Python or Alteryx or KNIME or whatever they can get their hands on.
To sum up, it is important to recognize that technically innovative features can distract us from the market value of a given business. Tech journalists spend most of their time discussing technical innovations as if this is what drives these businesses, when instead it is through subtle network effects that can arise out the absence or inclusion of user friction.
What does this mean for the future of technology and business?
Are we doomed to hop from one locked in platform to another for ever and ever?
The good news is that as this [pay walled] article in The Economist points out most people now realize this is a problem and governments are beginning to regulate the tech industry in much the same way other “winner take all” industries like utilities and banking have been regulated in the past.
The EU in particular appears to be working on legislation that if passed would open up companies like Google, Apple, and Facebook to more competition.
But as The Economist also points out “the devil is in the details” and getting regulation right is tricky (and worth the effort).
This means we should also be looking for solutions within technology itself.
History does not tolerate lock-in forever and eventually something better emerges out of these constraints. It is that “something better” that I am working on and I hope others are working on this same problem too. Much progress has been made due to the open source software movement, both for commercial and non-commercial users. But open source software is not enough because most of what I just described is ironically based on large swathes of open source software and yet here we are.
But, I can see a way forward from these silos.
How do you think we will break past these network effects and allow a more naked form of innovation to be the arbiter of success?